如何有效利用好CPU,主要在于如何写好SQL语句, 并优化数据库内部处理。
1. sql语句重用
1.1 硬解析与软解析
相信用过oracle的人,特别是用oracle做后端数据库开发的程序猿都听说过硬解析和软解析。
当一个sql语句提交后,oracle会首先检查一下共享缓冲池(shared pool)里有没有与之完全相同的语句,如果有的话只须执行软分析即可,否则就得进行硬分析。
硬解析之所以坑爹的原因是,它需要经解析,制定执行路径,优化访问计划等许多的步骤。不但耗费大量的cpu,更重要的是会占据重要的们闩(latch)资源,严重的影响系统的规模的扩大(即限制了系统的并发行),而且引起的问题不能通过增加内存条和cpu的数量来解决。
看一眼AWR报表,检查是不是有很多硬解析。下图的硬解析数和 time model statistics的hard parse elapsed time对应,可知该系统是否 是 解析敏感
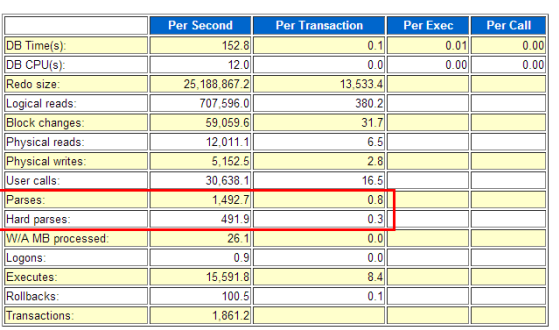
有时候当我们在oracle上对某些sql进行测试时,会发现第一次执行的sql比较慢,再次执行往往都比较快,这不仅仅是因为所需要的数据块已经读取到buffer cache中了,还因为再次执行的sql沿用的是上次执行的执行计划,并没有重新做解析。
因此假如我们需要测试相同sql不同的执行计划时,最好刷新一下当前session的shared pool。注意最好不要全局刷新,特别是在生产环境,这样会导致所有的sql都进行重新解析,可能会严重影响性能。
1.2 绑定变量
绑定变量的实质就是用于替代sql语句中的常量的替代变量,它能够使得每次提交的sql语句都完全一样。还记得前面说的”oracle会首先检查一下共享缓冲池(shared pool)里有没有与之完全相同的语句”没有?
类似这样:
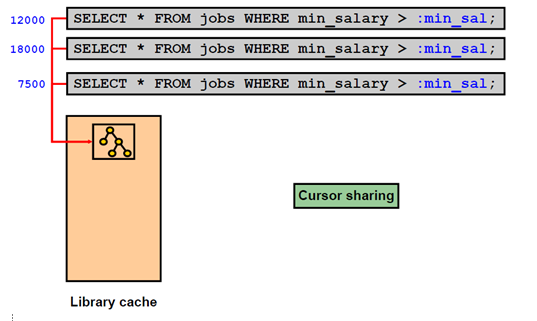
一般来说,在实际的开发场景,只要使用比较成熟的数据持久层框架例如mybatis等,基本都可以避免这种因为没有用绑定变量而产生的性能问题。
1.3 索引优化
索引优化这是大坑。。有空新开一篇再写吧
2. 表连接
在CBO(hash join只有在CBO才可能被使用到)模式下,优化器计算代价时,首先会考虑hash join。
- hash join的主要资源消耗在于CPU和内存(在内存中创建临时的hash表,并hash计算, Mem访问速度是Disk的万倍以上。)
- Nested Loop资源消耗在磁盘IO和CPU。
- sort merge的资源消耗主要在于磁盘IO(扫描表或索引)
相对来说,比较常见的还是hash join以及nested loop。
表连接科普参见 多表连接的三种方式
2.2 hash join
Hash join的工作方式是将一个表(通常是小一点的那个表)做hash运算,将列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做匹配。
2.2 nested loop
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是当一个关联表比较小的时候,效率会更高。
2.2 sort merge
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能。
总的来说,小表和大表连接用nested loop,大表和大表连接用hash join,关联列已经排序好的表连接推荐用sort merge(用的不多就是了)。
但凡事总有例外,具体的执行效果还是要根据具体情况看,有时候CBO推荐的执行计划未必是最好的, 此时你可以尝试使用hint或者修改sql语句来改变表连接。