索引是每种数据库都避不开的一个话题。很多人不管是DBA还是开发,对于索引的印象就是:sql慢?加个索引吧。但是为什么加了索引sql就能变快呢?加了索引是不是一定就会变快?怎么加索引效率会最高?
从B-tree索引讲起
索引就像是一本字典的查询页,你可以通过字母或者是偏旁快速定位需要查询的字。类似通过字母查询的是聚集索引(表中行的物理顺序与键值的逻辑索引顺序相同),反之通过偏旁的是非聚集索引(表中行的物理顺序与键值的逻辑索引顺序不相同)。扯远了,这里要讲的是b-tree索引。
oracle默认建的索引就是b-tree索引,他的工作方式如下:
很显然索引也是需要占用空间的,只是没有普通数据那么大而已。索引的大小跟数据量以及索引列的多少成正比。
一般来说,还是推荐将索引使用的空间与数据的tablespace分开来,索引建在索引专用的tablespace中,方便维护,同时也有助于查询效率提高。oracle的数据查询说到底就是数据块的读取,查询索引的时候,也是在读取数据块,索引数据块越集中,查询的速度越快,如果索引的数据块跟普通数据块一起放在同一个tablespace中,肯定相对比较分散,影响查询效率。
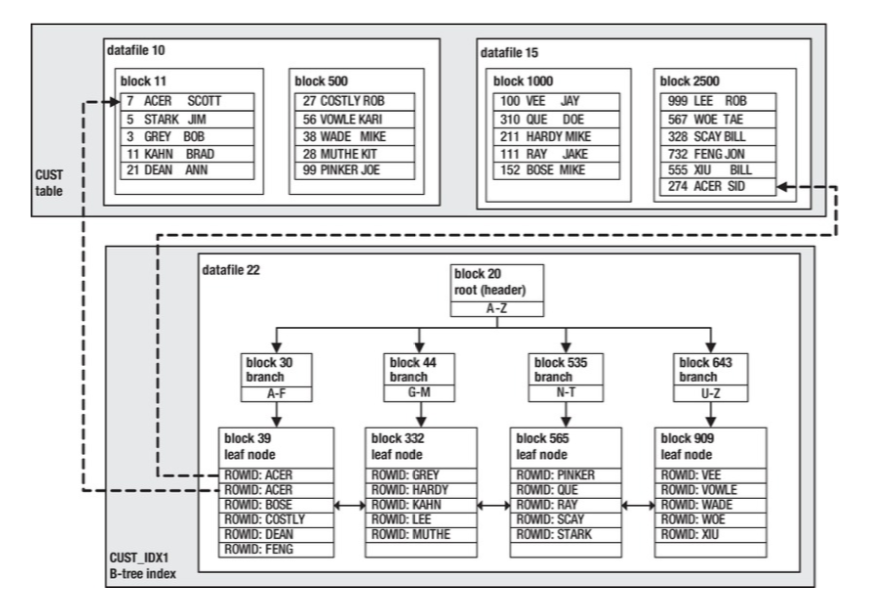
b-tree索引顾名思义就是一棵树。当我们要查询字段值为”ACER”的时候,oracle首先会读取索引的根节点,如图中的20号数据块。这个数据块中维护着子节点的信息,通过它可以往下找到子节点30号数据块,这个节点维护着下一个节点信息,在此表示所有首字母A-F的索引信息都是它的子节点。然后找到叶子节点39号数据块。这个数据块中包含索引字段值首字母是A-F的所有值以及相对应的rowid。
到此,假如你的sql只是需要查到索引的字段值得话,整个过程就到此结束了。但是如果还要对应的其他字段值,则还需通过上一步得到rowid去数据存储的tablespace中找到相应数据块。
发现什么没有?其实oracle的sql查数据最快的方法是直接用rowid查询啊,连索引扫描的时间都省掉了。
如何挑选索引列
- 定义一个主键列,oracle会自动为它建一个unique index
- 外键列通常是需要建索引的
- 在经常用到的列上建索引,特别是在where谓词中经常出现的
你大概会说上面三点基本就是废话。。
好吧,我们说点不是废话的:索引扫描的三种情形
1. sql所有需要的数据都在索引上
又分为两种情况:
index range scan.
在上图中,假如只要查询”ACER”,那么oracle只需读取3个block,同时在第三个block中挑出是”ACER”的值就可以了,此时用的就是range scan。index fast full scan.
还是上图,假如需要查询被索引的所有值或是大部分值,oralce优化器会认得此时用 index fast full scan最快,就是不挑了,把索引上的值都扫一遍
2. sql需要的数据不都在索引上
这个情况是最普遍的,即从B-tree索引讲起的第4点情况,反映在执行计划中就是 TABLE ACCESS BY INDEX ROWID
3. 不想走索引,就是这么任性
有时候即使表上有各种索引,oracle优化器还是会认为不走索引反而更快,比如全表扫描(TABLE ACCESS FULL)。
索引不是越多越好,也不是一个复合索引覆盖的列越多越好,需要综合考虑性能。建了索引之后也要查看一下执行计划,是不是确实用到了索引,
同时要看下sql的buffer read和physical read跟原先比如何。
bitmap索引稍及
我并没有用过bitmap索引,经验不多,所以就只能稍微介绍下。
bitmap索引即所谓的位图索引,它和b-tree索引最大的区别是适用于只有几个固定值的列,如性别、婚姻状况等,如果列的取值非常多则适用于b-tree索引。
另外位图索引适合静态数据,而不适合索引频繁更新的列。因为它所造成的行锁比较广,非常坑爹。举个例子,某张表上的性别列上是位图索引,有次将其中某一个人的性别从男改成女时,会将表上所有女性记录加锁,直到commit。可以想象假如更新频繁的话,会出现严重的锁等待事件
监控索引使用情况
在一个很大的数据库中,可能会有成百上千个索引分布在各个表上。随着时间的过去,可能其中很多索引都已经用不到了。虽然索引可以帮助加快数据查询的速度,但是相应也是有代价的。当表的数据有插入,更新,删除的变化时,表上的索引也需要更新,他会占用cpu和磁盘的资源,索引越多,占用的资源越多。所以对于这些已经没有在被使用的索引,可以删掉,节约资源。
1 | --对单独某个索引启用监控 |