本文主要通过一个具体的spark application来讲述spark job执行过程中关于stage划分,stage提交,task运行的流程。主要也是因为上篇的源码阅读只有纯粹的理论,所以希望能通过这篇实战将理论讲的更清楚一点。
RDD
RDD,全称为Resilient Distributed Datasets,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。在这些操作中,诸如map、flatMap、filter等转换操作,很好地契合了Scala的集合操作。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作(注意,reduceByKey是action,而非transformation),以支持常见的数据运算。
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区(partition),每个分区就是一个dataset片段。RDD可以相互依赖。
如图是一个比较简单的RDD数据流转图,P1,P2 代表各个RDD内的分区。
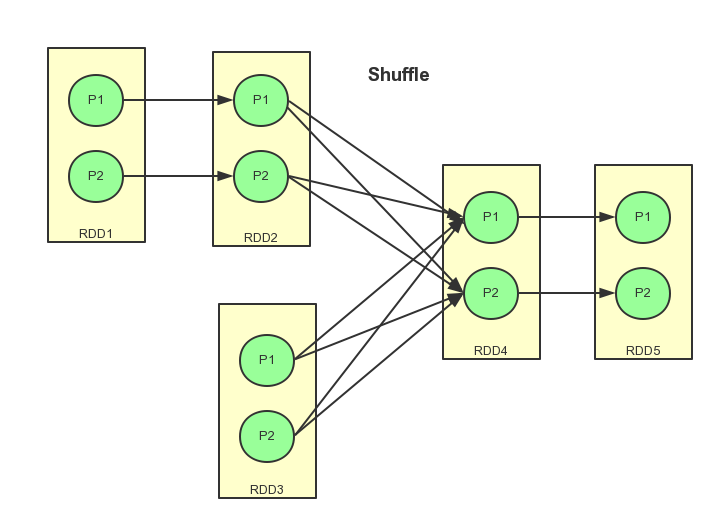
总结:
- 它是不变的数据结构存储
- 它是支持跨集群的分布式数据结构
- 可以根据数据记录的key对结构进行分区
- 提供了粗粒度的操作,且这些操作都支持分区
- 它将数据存储在内存中,从而提供了低延迟性
Partition
什么是partition
每个 partition 就是一个RDD的dataset片段,他支持比RDD更细粒度的操作
RDD 中有几个partition
初始由并行度决定。
1
2
3
4
5
6
7scala> val data1=Array(1,2,3,4,5,6)
data1: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> val rangePairs1 = sc.parallelize(data1, 3)
rangePairs1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:23
scala> rangePairs1.partitions.size
res2: Int = 3 //设置并行度为3之后,RDD rangePairs1 的partition个数也为3修改partition个数。
下面使用了两种修改partition数量的操作repartition和partitionBy。
从DebugString来看,partitionBy的操作代价要小于repartition,但是repartition的适用性比partitionBy广,具体怎么用根据实际情况来吧。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
251.repartition---
scala> val hashPairs1 = rangePairs1.repartition(6)
hashPairs1: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at repartition at <console>:25
scala> hashPairs1.partitions.size
res0: Int = 6
scala> println(hashPairs1.toDebugString)
(6) MapPartitionsRDD[21] at repartition at <console>:25 []
| CoalescedRDD[20] at repartition at <console>:25 []
| ShuffledRDD[19] at repartition at <console>:25 []
+-(3) MapPartitionsRDD[18] at repartition at <console>:25 []
| ParallelCollectionRDD[17] at parallelize at <console>:23 []
2.partitionBy----
scala> val hashPairs1 = rangePairs1.partitionBy(new HashPartitioner(6))
hashPairs1: org.apache.spark.rdd.RDD[(Int, Char)] = ShuffledRDD[1] at partitionBy at <console>:28
scala> hashPairs1.partitions.size
res0: Int = 6
scala> println(hashPairs1.toDebugString)
(6) ShuffledRDD[4] at partitionBy at <console>:32 []
+-(3) MapPartitionsRDD[3] at map at <console>:30 []
| ParallelCollectionRDD[2] at parallelize at <console>:26 []
partition 与 task 关系
spark 的每一个stage都包含了一个或多个task,task的数量取决于每个stage中最后一个RDD的partition数量。
Dependency
RDD 本身的依赖关系由 transformation() 生成的每一个 RDD 本身语义决定,每个RDD的getDependencies()定义RDD之间的数据依赖关系。
RDD 中 partition 依赖关系分为 NarrowDependency(窄依赖) 和 ShuffleDependency(宽依赖)
窄依赖 指父RDD的每一个分区最多被一个子RDD的分区所用,表现为
一个父RDD的分区对应于一个子RDD的分区
两个父RDD的分区对应于一个子RDD 的分区。
宽依赖 指子RDD的每个分区都要依赖于父RDD的所有分区,
Stage
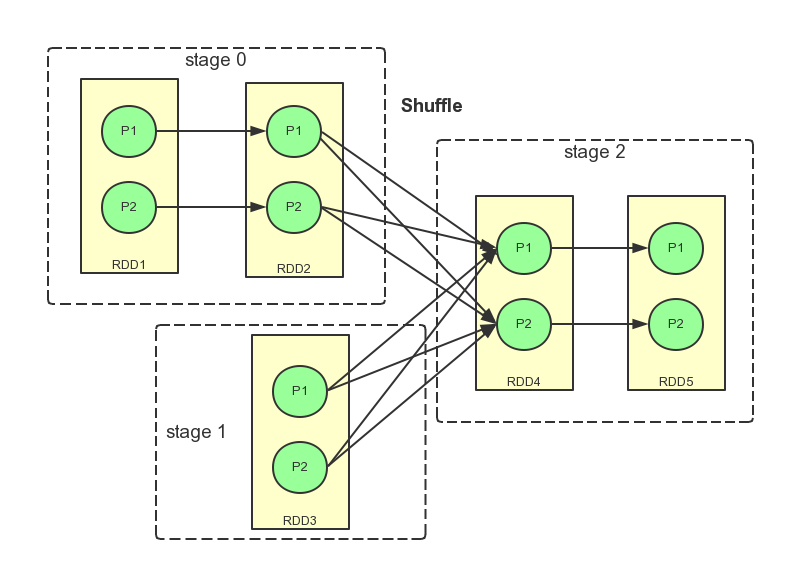
DAGScheduler对Stage的划分是spark任务调度的核心,在上篇 spark 源码阅读–job提交与执行过程 提到spark划分stage的总体思想是从最后的finallRDD出发反向递归访问逻辑执行图,每遇到宽依赖就断开,把之前沿途的窄依赖都加入同一个stage。于是对于本文开始的那个RDD数据流转图可以进行如下的划分。
实战
讲了这么多理论知识,下面准备结合一个具体的例子来验证一下spark job提交之后的各个过程。
首先构造一个稍复杂的spark job。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import org.apache.log4j.{Level, Logger}
import org.apache.spark._
object complexJob {
def main(args: Array[String]) {
//开启debug日志
Logger.getLogger("org").setLevel(Level.DEBUG)
Logger.getLogger("akka").setLevel(Level.DEBUG)
val sc = new SparkContext("local[3]", "ComplexJob test")
val data1 = Array[Int](1, 2, 3, 4, 5, 4, 3, 2, 1)
val data2 = Array[Char]('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i')
val dataRdd1 = sc.parallelize(data1, 3)
val dataRdd2 = sc.parallelize(data2, 3)
val dataRdd3 = dataRdd1.zip(dataRdd2)
val dataRdd4 = dataRdd3.groupByKey()
val dataRdd5 = dataRdd4.map(i => (i._1 + 1, i._2))
val data3 = Array[(Int, String)]((1, "A"), (2, "B"),
(3, "C"), (4, "D"))
val dataRdd6 = sc.parallelize(data3, 2)
val dataRdd7 = dataRdd6.map(x => (x._1, x._2.charAt(0)))
val data4 = Array[(Int, Char)]((1, 'X'), (2, 'Y'))
val dataRdd8 = sc.parallelize(data4, 2)
val dataRdd9 = dataRdd7.union(dataRdd8)
val result = dataRdd5.join(dataRdd9)
result.foreach(println)
println(result.toDebugString)
}
}
执行后打印DebugString如下:
1 | (4) MapPartitionsRDD[11] at join at complexJob.scala:31 [] |
从上面的DebugString中,已经可以获取很多信息包括
- RDD的转换
- stage的划分:每一个缺口的同级可以分为一个stage
- partition的数量:在RDD前面括号里的数字就代表当前stage最后一个RDD的paritition数量,由此也可知每个stage的task数量
DebugString有点像oracle的执行计划,虽然我们已经可以根据这个来划分stage,但是并没有太多的细节信息,所以还是想从代码出发,来详细解释一下stage为什么要这么划分,以及stage提交的流程,顺便也可以与DebugString相互验证。
流程图
根据代码,最终的流程图如下:

代码解读
从整体上看,最后的结果result来自dataRdd5.join(dataRdd9),所以我们可以首先将整个job拆成A,B两条线,分别对应dataRdd5和dataRdd9的处理流程。
- A线:
A1. 数组data1生成类型为ParallelCollectionRDD的dataRdd1,分区数为3。
A2. 数组data2生成类型为ParallelCollectionRDD的dataRdd2,分区数为3。
A3. 将dataRdd1和dataRdd2通过Transformation(zip)生成新的ZipPartitionsRDD(dataRdd3)。zip是一种变形的map,可以将两个数组根据相同的下标map成一个新的数组结构[(key1,value1),(key2,value2)..(keyN,valueN)]。要注意的是两个RDD的partition数必须相等,否则不能zip。
A4. dataRdd3通过Transformation(groupBykey)生成ShuffledRDD(dataRdd4)。注意此处有shuffle。
A5. dataRdd4通过Transformation(map)将所有的key值加1后生成新的MapPartitionsRDD(dataRdd5),分区数为3。
dataRdd5生成完毕
- B线:
B1. 数组data3生成类型为ParallelCollectionRDD的dataRdd6,分区数为2。
B2. dataRdd6通过Transformation(map)生成MapPartitionsRDD(dataRdd7)
B3. 数组data4生成类型为ParallelCollectionRDD的dataRdd8,分区数为2。
B4. dataRdd7 与dataRdd8通过Transformation(union)生成新的UnionRDD(dataRdd9),分区数为4
dataRdd9生成完毕
最后得到result=dataRdd5.join(dataRdd9),分区数为4。注意此处有shuffle。调用join()的时候并不是一次性生成最后的MapPartitionsRDD,而是首先会进行 cogroup(),得到<K, (Iterable[V1], Iterable[V2])>类型的MapPartitionsRDD,然后对 Iterable[V1] 和 Iterable[V2] 做笛卡尔集,最后生成新的MapPartitionsRDD,所以在join后会产生3个RDD。
stage 划分
根据DAGScheduler的逻辑,首先从最后的finalRDD(本文为result)开始向前递归访问。
当到达join时,发现有子RDD(result)的每个分区都要依赖于父RDD(dataRdd5和dataRdd9)的所有分区,所以是shuffleDependency,。于是把join之后的所有RDD划分为一个stage,标记为stage3。
注意,假如dataRdd5,dataRdd9的partitioner也是HashPartitioner,且partition数量与result的相同,那么他们之间的依赖就变成了narrowDependency,属于两个(会有多个吗?不,spark只支持两两join)父RDD的分区对应于一个子RDD的分区的情况,这个join()变成了hashjoin()。
继续往前,先看A线部分,当递归访问到A4步骤(groupBykey)时,判断dataRdd3–>dataRdd4之间的依赖为shuffleDependency,于是将dataRdd4和dataRdd5划分为新的stage,标记为stage1。
A线继续往前,到zip又遇到依赖,属于两个父RDD(dataRdd1&dataRdd2)的分区对应于一个子RDD(dataRdd3)的分区的情况,判断为narrowDependency,而dataRdd1和dataRdd2之前已经没有别的RDD存在,于是将dataRdd1,dataRdd2,dataRdd3划分为一个新的stage,标记为stage0。
A线已经结束,现在看B线部分。在B线的递归路径中发现有union(),union()是将两个RDD简单合并在一起,并不改变 partition里面的数据。它是一种RangeDependency,属于narrowDependency的一种。继续往前遍历,发现整个B线中都不存在shuffleDependency,所以可以将整个B线划分为新的stage,标记为stage2。
到此对整个job的stage划分已经结束,总共分为4个stage。
stage提交
stage提交的过程,也就是job执行的过程。根据前一篇的spark源代码解读,DAGScheduler首先会调用finalStage = newStage()进行stage划分,这一步已经在上文完成,那么接下来就是DAGScheduler调用submitStage,提交finalStage。
在本文中例子中的finalStage就是最后的stage3,提交stage3之后,递归查找parentStage,发现stage3依赖于stage1和stage2。
1
2
3
4
5
6
7
815/04/27 19:03:28 INFO DAGScheduler: Registering RDD 2 (zip at complexJob.scala:17)
15/04/27 19:03:28 INFO DAGScheduler: Registering RDD 4 (map at complexJob.scala:19)
15/04/27 19:03:28 INFO DAGScheduler: Registering RDD 8 (union at complexJob.scala:29)
15/04/27 19:03:28 INFO DAGScheduler: Got job 0 (foreach at complexJob.scala:32) with 4 output partitions (allowLocal=false)
15/04/27 19:03:28 INFO DAGScheduler: Final stage: Stage 3(foreach at complexJob.scala:32)
15/04/27 19:03:28 INFO DAGScheduler: Parents of final stage: List(Stage 1, Stage 2)
15/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 3)
15/04/27 19:03:28 DEBUG DAGScheduler: missing: List(Stage 1, Stage 2)提交stage1和stage2,将stage3放入waitingStages。
1
215/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 1)
15/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 2)stage1 发现parentStage:stage0,提交stage0,将stage1放入waitingStages。
1
2
315/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 1)
15/04/27 19:03:28 DEBUG DAGScheduler: missing: List(Stage 0)
15/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 0)stage0没有找到parentStage,可以立即执行,调用submitMissingTasks,生成类型为ShuffleMapTask的tasks,task的数量与stage0中最后一个Rdd partition数量相等为3。
1
2
3
4
5
6
715/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 0)
15/04/27 19:03:28 DEBUG DAGScheduler: missing: List()
15/04/27 19:03:28 INFO DAGScheduler: Submitting Stage 0 (ZippedPartitionsRDD2[2] at zip at complexJob.scala:17), which has no missing parents
15/04/27 19:03:28 DEBUG DAGScheduler: submitMissingTasks(Stage 0)
15/04/27 19:03:28 INFO DAGScheduler: Submitting 3 missing tasks from Stage 0 (ZippedPartitionsRDD2[2] at zip at complexJob.scala:17)
15/04/27 19:03:28 DEBUG DAGScheduler: New pending tasks: Set(ShuffleMapTask(0, 2), ShuffleMapTask(0, 1), ShuffleMapTask(0, 0))
15/04/27 19:03:28 INFO TaskSchedulerImpl: Adding task set 0.0 with 3 tasksstage2没有找到parentStage,可以立即执行,调用submitMissingTasks,生成类型为ShuffleMapTask的tasks,task的数量与stage2中最后一个Rdd partition数量相等为4。
1
2
3
4
5
615/04/27 19:03:28 DEBUG DAGScheduler: submitStage(Stage 2)
15/04/27 19:03:28 DEBUG DAGScheduler: missing: List()
15/04/27 19:03:28 DEBUG DAGScheduler: submitMissingTasks(Stage 2)
15/04/27 19:03:28 INFO DAGScheduler: Submitting 4 missing tasks from Stage 2 (UnionRDD[8] at union at complexJob.scala:29)
15/04/27 19:03:28 DEBUG DAGScheduler: New pending tasks: Set(ShuffleMapTask(2, 0), ShuffleMapTask(2, 3), ShuffleMapTask(2, 2), ShuffleMapTask(2, 1))
15/04/27 19:03:28 INFO TaskSchedulerImpl: Adding task set 2.0 with 4 tasksstage0的task完成后通知dagScheduler,当stage0中所有的task都完成后,将stage0的执行结果注册到mapOutputTrackerMaster给下一个被依赖的stage1使用。然后提交等待中的stage1。
1
2
3
4
5
615/04/27 19:03:28 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
15/04/27 19:03:28 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
15/04/27 19:03:28 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
15/04/27 19:03:28 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 883 bytes result sent to driver
15/04/27 19:03:28 INFO Executor: Finished task 2.0 in stage 0.0 (TID 2). 883 bytes result sent to driver
15/04/27 19:03:28 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 883 bytes result sent to driverstage2的task全部完成后将结果注册到mapOutputTrackerMaster给下一个被依赖的stage3使用。等待stage1的tasks结束
1
2
3
4
5
6
7
815/04/27 19:03:28 INFO Executor: Running task 0.0 in stage 2.0 (TID 3)
15/04/27 19:03:29 INFO Executor: Running task 1.0 in stage 2.0 (TID 4)
15/04/27 19:03:29 INFO Executor: Running task 2.0 in stage 2.0 (TID 5)
15/04/27 19:03:29 INFO Executor: Running task 3.0 in stage 2.0 (TID 6)
15/04/27 19:03:29 INFO Executor: Finished task 1.0 in stage 2.0 (TID 4). 884 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 2.0 in stage 2.0 (TID 5). 884 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 0.0 in stage 2.0 (TID 3). 884 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 3.0 in stage 2.0 (TID 6). 884 bytes result sent to driverstage0结束之后,stage1调用submitMissingTasks,生成类型为ShuffleMapTask的tasks,task的数量与stage1中最后一个Rdd partition数量相等为3。
1
2
3
4
515/04/27 19:03:29 INFO DAGScheduler: Submitting Stage 1 (MapPartitionsRDD[4] at map at complexJob.scala:19), which is now runnable
15/04/27 19:03:29 DEBUG DAGScheduler: submitMissingTasks(Stage 1)
15/04/27 19:03:29 INFO DAGScheduler: Submitting 3 missing tasks from Stage 1 (MapPartitionsRDD[4] at map at complexJob.scala:19)
15/04/27 19:03:29 DEBUG DAGScheduler: New pending tasks: Set(ShuffleMapTask(1, 2), ShuffleMapTask(1, 1), ShuffleMapTask(1, 0))
15/04/27 19:03:29 INFO TaskSchedulerImpl: Adding task set 1.0 with 3 tasksstage1的tasks全部完成后将结果注册到mapOutputTrackerMaster给下一个被依赖的stage3使用。
1
2
3
4
5
615/04/27 19:03:29 INFO Executor: Running task 1.0 in stage 1.0 (TID 8)
15/04/27 19:03:29 INFO Executor: Running task 0.0 in stage 1.0 (TID 7)
15/04/27 19:03:29 INFO Executor: Running task 2.0 in stage 1.0 (TID 9)
15/04/27 19:03:29 INFO Executor: Finished task 1.0 in stage 1.0 (TID 8). 1100 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 2.0 in stage 1.0 (TID 9). 1100 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 0.0 in stage 1.0 (TID 7). 1100 bytes result sent to driverstage3的parentStage已经全部结束任务,提交stage3,生成类型为ResultTask的tasks,task的数量与stage3中最后一个Rdd partition数量相等为4。
1
2
3
4
5
6
7
8
9
10
1115/04/27 19:03:29 INFO DAGScheduler: Stage 1 (map at complexJob.scala:19) finished in 0.149 s
15/04/27 19:03:29 INFO DAGScheduler: looking for newly runnable stages
15/04/27 19:03:29 INFO DAGScheduler: running: Set()
15/04/27 19:03:29 INFO DAGScheduler: waiting: Set(Stage 3)
15/04/27 19:03:29 INFO DAGScheduler: failed: Set()
15/04/27 19:03:29 INFO DAGScheduler: Missing parents for Stage 3: List()
15/04/27 19:03:29 INFO DAGScheduler: Submitting Stage 3 (MapPartitionsRDD[11] at join at complexJob.scala:31), which is now runnable
15/04/27 19:03:29 DEBUG DAGScheduler: submitMissingTasks(Stage 3)
15/04/27 19:03:29 INFO DAGScheduler: Submitting 4 missing tasks from Stage 3 (MapPartitionsRDD[11] at join at complexJob.scala:31)
15/04/27 19:03:29 DEBUG DAGScheduler: New pending tasks: Set(ResultTask(3, 2), ResultTask(3, 0), ResultTask(3, 1), ResultTask(3, 3))
15/04/27 19:03:29 INFO TaskSchedulerImpl: Adding task set 3.0 with 4 tasksstage3的task的结束时判断此task是不是最后一个task,如果是则job结束。
1
2
3
4
5
6--output result on each task finish
15/04/27 19:03:29 INFO Executor: Finished task 1.0 in stage 3.0 (TID 11). 886 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 2.0 in stage 3.0 (TID 12). 886 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 3.0 in stage 3.0 (TID 13). 886 bytes result sent to driver
15/04/27 19:03:29 INFO Executor: Finished task 0.0 in stage 3.0 (TID 10). 886 bytes result sent to driver
15/04/27 19:03:29 INFO DAGScheduler: Job 0 finished: foreach at complexJob.scala:32, took 1.004075 s
尾声
本文对于spark job执行过程中关于stage划分,stage提交,task运行的流程已经全部讲解完毕。
由于本人才疏学浅以及时间的关系,如有错漏之处,请指出来我会重新修改。