执行计划?
执行计划是sql在数据库中最终的执行路径,包括索引的扫描,数据的读取,过滤,连接,排序等等一系列过程。就像平常在生活中你为了完成一个任务,需要经过很多步骤,如果没有很好的统筹规划,任务时间会不断延长。所以sql的效率跟它的执行计划息息相关,同一个sql可能会有很多不一样的执行计划,基于CBO的oracle会在其中挑选出它认为最快的执行计划进行执行。下面这个流程图展现了优化器选择执行计划过程:
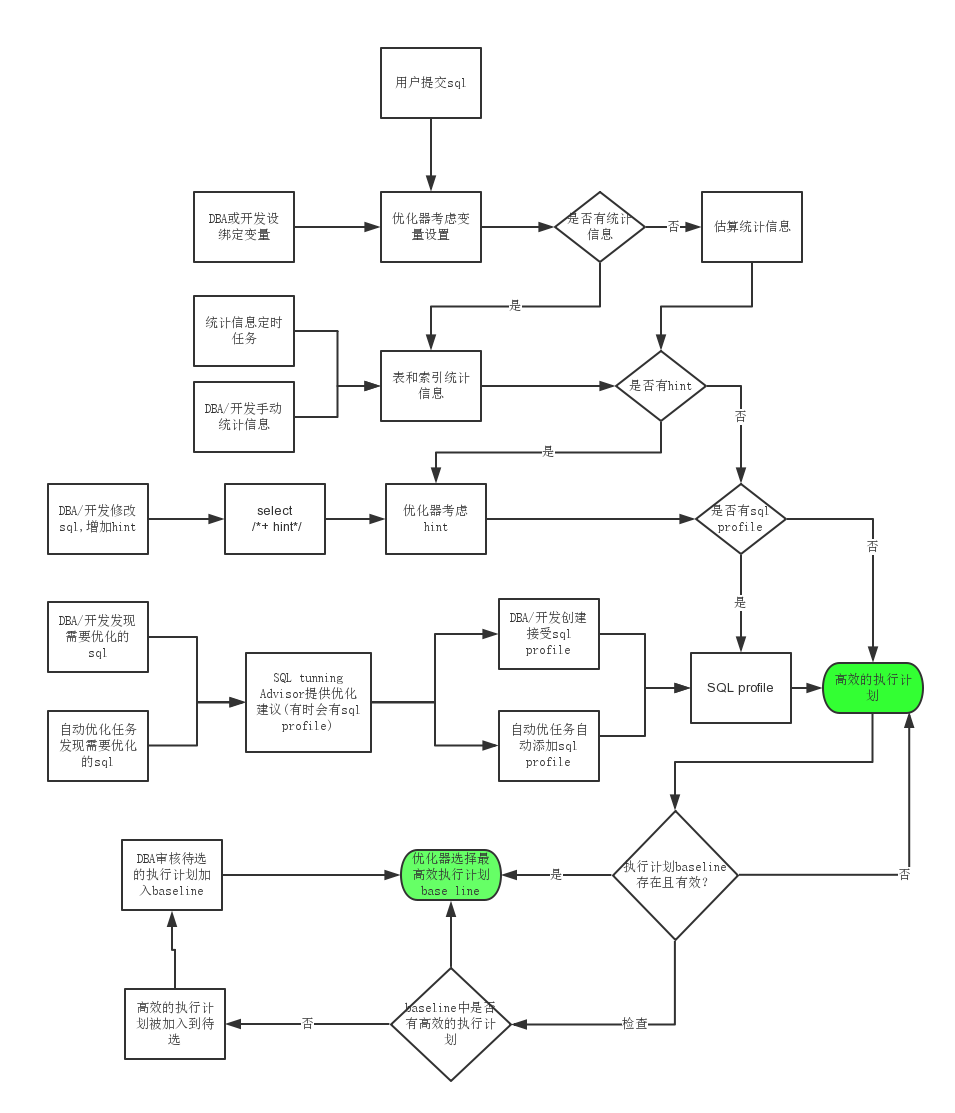
从上面的流程图可以知道一个高效良好的执行计划需要考虑的因素有
- 绑定变量。//还记得CPU优化篇的sql重用吗
- 统计信息。oracle默认会在每天的晚上以及周末触发自动收集数据改变量在10%以上的表的统计信息。如果统计信息过于陈旧,DBA或者开发也可以手动提交收集统计信息任务。
- hint。hint会强制指定执行计划的路径,比如select /*+ use_hash*/ ,不管优化器怎么认为表连接应该使用nested loop更加效率,都会强制使用hash连接
- sql profile。定义
- sql plan。sql profile vs plan baseline
怎么查看执行计划
1. Explain Plan For SQL
- 不实际执行SQL诧句,生成的计划未必是真实执行的计划
- 必须要有plan_table
1 | EXPLAIN PLAN FOR |
2. SQLPLUS AUTOTRACE
- 除set autotrace traceonly explain外均实际执行SQL,但仍未必是真实计划
- 必须要有plan_table
3. 其他第三方工具
- sqldeveloper
- toad(收费,比sqldeveloper强大,细节丰富)
4. 最靠谱的方法
为什么上文说未必是真实的计划呢?这里的指的是实际生产环境使用的执行计划和你手动用上文的方法查看某个sql的执行计划是有可能有差异的。所以最靠谱的办法是在生产环境找到已经执行过的sql或者是正在执行的sql的sql id,然后根据这个id去查看他的执行计划
查询历史sql和sql id
1 | select sql_id,sql_text from v$SQL Where |
查询正在执行的sql和sql id
1 | select a.username, a.sid,b.SQL_TEXT, b.SQL_FULLTEXT,b.sql_id |
note:
V\$SQL, V\$SQLAREA, V\$SQLTEXT三个视图的区别:
V\$SQL:CHILD CURSOR DETAILS FOR V\$SQLAREA
V\$SQLAREA:SHARED POOL DETAILS FOR STATEMENTS/ANONYMOUS BLOCKS
V\$SQLTEXT:SQL TEXT OF STATEMENTS IN THE SHARED POOL
V\$SQL的每一行表示的是每一个SQL语句的一个版本,而V\$SQLAREA存放的是相同语句不同版本一个GROUP BY汇总。
V\$SQL及V\$SQLAREA存放着统计信息在调优时使用居多,但其SQL是不全的,如果想获得完整的SQL需使用V\$SQLTEXT。
精确查询详细执行计划
1 | alter session set STATISTICS_LEVEL = ALL; --不设置无法获得A-ROWS等信息,A-Rows 是实际执行时返回的行数 |
执行计划的执行顺序
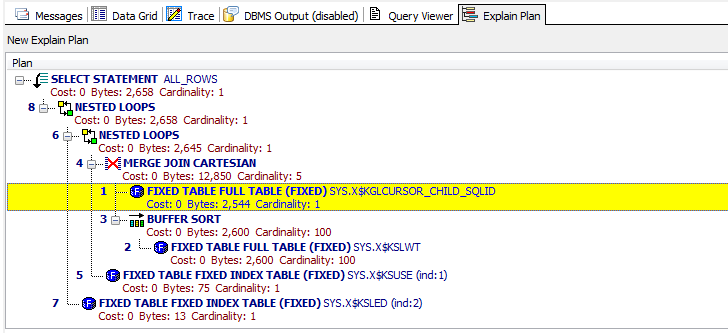
toad看这个最方便,可以直接显示执行顺序。如图中的12345678就是:
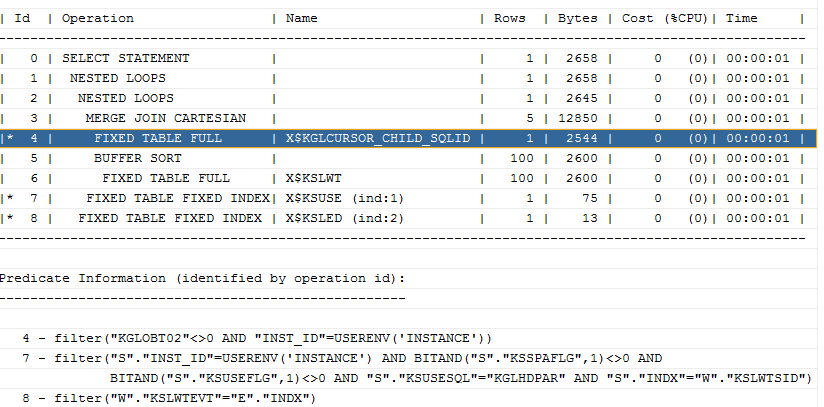
但是如果没有toad的话,通常显示的结果会是这样,要注意的是这里的id并不是顺序:
note:
- Id 分配给执行计划中每一个步骤的一个数字 每个步骤(执行计划中的行,戒树中的节点)代表行源 (row source)。
- Operation 该步骤实施的内部操作名 id=0的operation一般是 SELECT/INSERT/UPDATE/DELETE Statement
- Name 该步骤操作的表戒者索引名
- Rows CBO基亍统计信息估计该操作将返回的行数
- Bytes CBO基亍统计信息估计该操作将返回的字节数
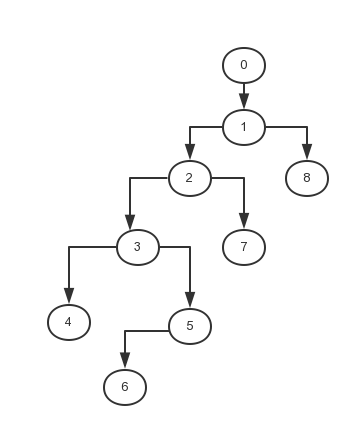
如果你学过二叉树的后序遍历的话,其实也很简单。首先我们先将这个图根据缩进转化成一个树。然后对这个树进行一下后续遍历,这个遍历的顺序(4 -> 6 -> 5-> 3 -> 7 -> 2 -> 8 -> 1 -> 0)就是执行顺序。
如何通过执行计划优化sql
- 在计划中,驱动表具有最强的过滤性。
- 每个步骤的联接顺序都可保证返回给下一步的行数最少(即,联接顺序应使系统转到尚未使用的最强过滤器)。
- 就返回的行数而言,相应的联接方法是适合的。例如,返回的行很多时,使用索引的嵌套循环联接可能不是最佳方法。
- 高效地使用视图。查看 SELECT 列表,确定访问的视图是否必需。
- 是否存在预料之外的笛卡尔积(即使对于小表,也是如此)。
- 高效地访问每个表:考虑 SQL 语句中的谓词和表的行数。查找可疑活动,例如对行数很多的表执行全表扫描(在 WHERE 子句中有谓词)。而对于小表,或根据返回的行数利用更好的联接方法(例如 hash_join)时,全表扫描也许更有效。
参考: